

XML Storage in XTC
In XTC, tailor-made node labeling and various index types are available to support flexible XML document storage and processing. Several compression techniques especially developed for XML storage, help to reduce space consumption and IO costs. Nearly all storage preferences can be fine-tuned for specific workloads. However, the default preferences serve in most situations very well.
XML Document Here is a sample XML document.
|
|
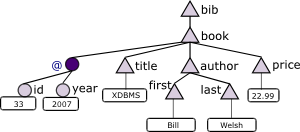
Tree RepresentationTypically XML documents are represented as trees. The bib element represents the root of the tree. Text content is captured in the boxes on the tree's leaves. |
|
DeweyID-labeled Document TreeSimilar to the RID/TID concept in relational databases, in XML documents the nodes carry unique identifiers (labels). Besides range-based labeling schemes, the DeweyID, DLN, or OrdPath schemes support the most flexibility that is important for database processing.
|
|
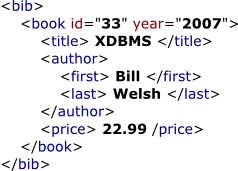

DeweyID Properties
XML document processing requires stable node labels that can be dynamically assigned. DeweyIDs fulfill this requirement very well. Furthermore, they support an overflow mechanism that allows for effective prefix compression.

Path SynopsisSimilar to the concept of a Dataguide, a so-called path synopsis represents a path summary of all paths occuring in an XML document. Each path instance gets a PCR (path class reference). This small data structure, which can be kept in main memory, is equipped with statistical information, and helps to store (see elementless storage mapping), process, and index XML documents. |
|
| |


Storage LayoutIn XTC, two different storage modes are supported: Full (also called node-oriented) storage mapping and the elementless (or path-oriented) storage mapping. | |
Full Storage Mapping (node-oriented)
| <image> |
Elementless Storage Mapping (path-oriented)
| <image> |