

XML Similarity Joins
Motivation
As XML continues its path to becoming the universal information model, large-scale XML repositories proliferate. Very often, such XML repositories are non-schematic or have multiple, evolving, or versioned schemas. In fact, a prime motivation for using XML to directly represent pieces of information is the ability of supporting ad-hoc or “schema-later” settings [1,2,3]. For example, the flexibility of XML can be exploited to reduce the upfront cost of data integration services, because documents originated from multiple sources can be stored without prior schema reconciliation and queried afterwards in a best-effort manner—such an approach to data integration is often referred to as dataspace systems [4]. As another example, features of the XML data model such as optional elements and mixed content allow incremental schema design on operational databases without requiring data migration; and on the application side, query integrity on evolving schemas can be preserved by using the descendant relationship to address parts of XML documents [1].
Of course, the flexibility of XML comes at a price: loose data constraints can lead to severe data quality problems, because the risk of storing inconsistent and incorrect data is greatly increased. A prominent example of such problems is the appearance of the so-called fuzzy duplicates, i.e., multiple and non-identical representations of a real-world entity. Complications caused by such redundant information abound in common business practices. Some examples are misleading results of decision support queries due to erroneously inflated statistics, inability of correlating information related to the same customer, and unnecessarily repeated operations, e.g., mailing, billing, and leasing of equipment. The problem of identifying fuzzy duplicates is commonly referred to as the entity matching (EM) problem.
Similarity join is a fundamental operation to support EM applications. This particular kind of join operation employs a predicate of type sim(r,s) >= t, where r and s are operand objects to be matched, sim is a similarity function, and t is a constant threshold. In typical EM processes, pairs satisfying a similarity join can be classified as potential duplicates and selected for later analysis.
In relational databases, fuzzy duplicates arise due to a variety of reasons, such as typographical errors and misspellings during data entry, incomplete information, and differing naming conventions when multiple and independent data sources storing overlapping information are integrated. In XML databases, deviations in documents representing the same real-world entity may arise not only due to varying content information, but also because structure can diverge. For example, two documents containing approximately or exactly the same data can be arranged in quite different structures. Moreover, even documents following the same schematic rule (i.e., a DTD or XML Schema) may present structural heterogeneity owing to the presence of optional elements or attributes. Therefore, to perform similarity joins on XML datasets, the similarity predicate should address the hierarchical structure of the documents.

As an example, consider the illustration on the left side, which shows an XML tree containing patient demographic information from a hospital. Although subtrees a) and b) refer to the same patient, it would be extremely difficult for an EM application to correctly identify them as fuzzy duplicates. The data in subtree a) is arranged by patient, while the data of subtree b) is arranged by study. Further, there is the extra element relatives in subtree a). Moreover, there are typos and use of different abbreviation conventions within the content of the two subtrees.
Database management systems are convenient platforms to provide support for similarity joins. Joining data based on some criterion is a primitive DBMS operation and several built-in components of off-the-shelf DBMSs, such as indexes, statistics, and physical operators, can be leveraged for realization of similarity operators. As a result, DBMSs can play a pivotal role in generic EM solutions instead of merely serving as an expensive and underused file system.
In a broader view, embedding of similarity operators into database engines lies at the core of the long-term goal of integrating database and information retrieval technologies (DB/IR integration) [5]. The interest in DB/IR integration has been (re)gaining a strong momentum over the last few years due to a confluence of emerging and interrelated demands: automatic ranking and keyword search in relational databases to improve support of text data and to increase database usability [6]; structured query models for IR engines, e.g., faceted search and entity search; and managing of structured data on the Web—such structured data has increasingly been accessed from static HTML tables and from the Deep Web, distilled from unstructured data by large-scale information extraction applications, and generated by Web 2.0 technologies such as mashups and social tagging [7]. In all these scenarios, there is the need of seamless coupling of structured and unstructured data, which is best served by an integrated DB/IR architecture. Further, because the XML data model is the common choice to describe semi-structured data, XML databases systems are natural candidates to provide DB/IR integration.
Here, we investigate the effective and efficient realization of XML similarity joins within XTC (XML Transaction Coordinator), our native XML database system. In this context, our goal is to exploit DBMS internals (e.g. physical operators and indexes) to obtain high-quality results and speed-up similarity processing without negatively interfering with the operation of other components in the system. Specifically, we address the design of structure-conscious XML similarity functions, combination of structural and textual similarity, support to entity description selection, implementation of efficient physical operators, and seamless integration of similarity operators into the XTC query engine. Next, we provide a short description of our work on each of these aspects.
General Strategy
As key design decision, we focus on the class of token-based similarity functions (aka set-overlap-based similarity functions). This class of functions ascertains the similarity between two objects of interest, i.e., XML trees, by measuring the overlap between token sets generated from these objects. This approach has three main advantages. First, we can measure textual and structural similarity between XML trees, jointly or in isolation, by operating on token sets representing text, structure, or both, in a unified framework. Second, we can obtain a very rich similarity space by varying the methods for generating token sets, associating weights to set elements (weighting schemes), measuring the set overlap, or any combination thereof. Third, token-based similarity functions are inexpensive to calculate, and it is possible to leverage a wealth of techniques for set similarity joins on strings (e.g., [8, 9])
Structural Similarity Functions
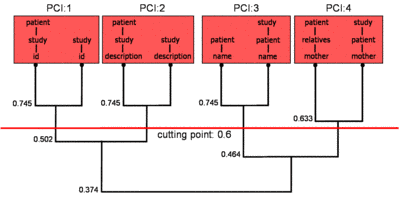
We developed a new method to generate structural token sets from XML trees. Our method applies a clustering algorithm on a path synopsis of XTC to produce compact and high-quality structural representations of XML documents. The resulting similarity function is shown to produce more accurate results than competing approaches while delivering much shorter token sets (bound by the number of paths in an XML tree). Moreover, the structural tokens lend themselves to very compact representations and can be generated for free with the support of a slightly adapted path synopsis. The figures below show the result of the clustering algorithm (on the left) and an XTC path synopsis equipped with the so-called Path Cluster Identifiers (PCI), which are used as structural tokens (on the right). For more details, see our paper.
|
|
|

Combination of Textual and Structural Similarity
Many approaches to XML similarity evaluation focus on structural similarity only; text nodes are either stripped away, before the matching process is initiated or only simple equality operations on text values are considered. While structural information certainly conveys useful semantic information, most of the discriminating power of real-life XML data, i.e., the items identifying information, which allow to distinguish documents in a collection from each another (e.g., keys), is assumed to be represented by text nodes. As a result, the resulting similarity notion is often too “loose” for EM applications or ineffective for datasets having poor textual quality. Considering textual and structural similarity together brings up the issue of combining similarity evaluation results, which is commonly referred to as the combination of evidence problem. While combination of evidence is necessary for structured data if multiple fields are used for similarity calculation, the duality of structure and text makes it an inherent component when assessing the similarity of XML trees. Combining structural and textual similarity is not trivial, however. The common solution of adopting a linear combination of similarity function values is problematic. Besides having different semantics, text and structural patterns usually present very variable frequency distributions across different datasets; optimal weights for the corresponding similarity results are likely to vary accordingly. As a result, there is a strong dependency on comprehensive training data (for supervised learning approaches) or intensive user guidance, both of them are not available in many real-world scenarios.
To overcome this problem, we introduced an extension of the original definition of pq-grams [10], the so-called extended pq-grams (epq-grams), to derive tokens combining structure and content from XML trees. The figure below shows three versions of eqp-grams, which jointly use textual and structural information. The technique is described in this paper. And here, we describe another way to avoid weight parameters for similarity operators based on token-level similarity combination.

Entity Description Selection
Frequently, only part of the available information about an entitiy is interesting for similarity matching. For example, while author_name and title are very significant in a database about publications, year_of_publication is expected to be much less useful. Such interesting pieces of information constitute the entity description, which is exploited to identify fuzzy duplicates. For structured data, entity description elements are usually gathered and placed in a single location (e.g., in a table in case of relational databases) before the EM process begins. In heterogeneous XML datasets, however, such elements may be dispersed in different parts of the XML trees owing to the structural heterogeneity. Using schema-aware query languages like XQuery or XPath to collect all necessary entity information is impractical, because the user may have only limited knowledge about the underlying structure. Even if the structure is known, it would be clumsy and error-prone to specify multiple queries using strict structural constraints, because the unified schema of heterogeneous XML datasets is often very complex. A better approach is to adopt a flexible query model based on XML search [11]: structural constraints are interpreted approximately, i.e., the structural context of the entity descriptions do not need to match exactly the structural constraints expressed in the query. Complementary to the flexible query model, it is important to provide the user with interactive exploration capabilities to support the selection of interesting entity descriptions.
To support entity description selection, we devised a cluster prototype for each path cluster (see structural similarity functions above), i.e., a structure subsuming all paths contained in a cluster. This structure is then used to match (partial) paths against its cluster prototype. In this context, the benefit of cluster prototypes is two-fold: users can specify, which part of the documents will constitute their textual representation, with vague knowledge about the underlying structure and existing clusters can be updated, as operations such as insertion of a new document add a new path to the path synopsis. To support exploratory queries before the actual similarity join evaluation takes place, we return several pieces of statistical information about the top-k results, such as cluster frequency in the collection and mean text value length of text nodes appearing in the cluster set. The user can therefore reformulate the query if, for example, the returned cluster set appears only in a few subtrees or is related to a part of the document with predominance of lengthy free text. The figure below on the left hand illustrates this process.
Further, we designed a little memory-resident inverted list index to represent the set of cluster prototypes (figure below on the right hand) and efficiently match selection queries against them by employing well-known IR optimizations. For more details, take a look at our paper. Another strategy for entity description selection based search predicates is described here.
|
|


Set Similarity Joins
After having converted XML trees into sets of tokens, the remaining processing consists of identifying those sets sharing enough tokens, i.e., a set similarity join has to be performed. To this end, we have developed a new index-based algorithm for set similarity joins. Following a completely different approach from previous work, we focus on the reduction of the computational cost for candidate generation as opposed to a lower number of candidates. For this reason, we introduce the concept of min-prefix, a generalization of the prefix filtering concept [8, 9] which allows to dynamically and safely minimize the length of the inverted lists; hence, a larger number of irrelevant candidate pairs are never considered and, in turn, a drastic decrease of the candidate generation time is achieved. As a side-effect of our approach, the workload of the verification phase is increased. Therefore, we optimized this phase by stopping as early as possible the computation of candidate pairs that do not meet the overlap constraint. Finally, we improved the overlap score accumulation by storing scores and auxiliary information within the indexed set itself instead of using a hash-based map. Our experimental findings confirm that our algorithm consistently outperforms previous ones for both unweighted and weighted sets. The figure below depicts the relationship between different prefix types. For more details, see our paper.

Embedding into XTC
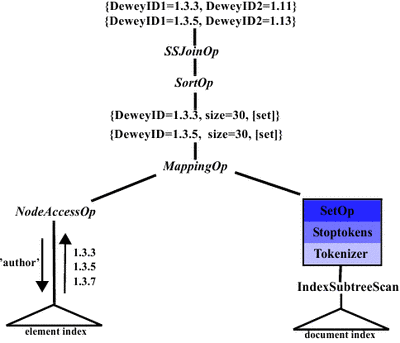
We addressed the integration of our framework into XTC's architecture. We focus on the system embedding of similarity operators on top of the storage layer by using index-based location of qualified XML fragments (element index and document index), leveraging of physical algebra for XPath processing, and enhancing performance with pipelined evaluation. The resulting operators can be combined (e.g., by delivering the resulting nodes or DeweyIDs in document order) with regular XML queries to compose processing logic enabling more complex EM solutions. The figure below shows a physical operator tree for an XML similarity join. More details about the embedding of similarity operators into the XTC architecture can be found here.
Contact
References
[1] Sedlar, E.: Managing Structure in Bits & Pieces: the Killer Use Case for XML. In: Proceedings of the ACM SIGMOD Int. Conf. on Management of Data (SIGMOD 2005), pp. 818-821, Baltimore, Maryland, USA, 2005.
[2] Balmin, A., Beyer, K. S., Özcan, F., Nicola, M.: On the Path to Efficient XML Queries. In: Proceedings of the 32nd Int. Conf. on Very Large Data Bases (VLDB 2006), pp. 1117-1128, Seoul, Korea, 2006.
[3] Liu, Z. H., Murthy, R.: A Decade of XML Data Management: An Industrial Experience Report from Oracle. In: Proc. of the 25th Int. Conf. on Data Engineering (ICDE'09), pp. 1351-1362, Shanghai, China, 2009.
[4] Halevy, A. Y, Franklin, M. J., Maier, D.: Principles of dataspace systems. In: Proc. of the 25th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, pp. 1-9, Chicago, Illinois, USA, June 2006.
[5] Chaudhuri, S., Ramakrishnan, R., Weikum, G.: Integrating DB and IR Technologies: What is the Sound of One Hand Clapping? In: 2nd Biennial Conf. on Innovative Data Systems Research (CIDR 2005), pp. 1-12, Asilomar, CA, USA, 2005.
[6] Jagadish, H. V., Chapman, A., Elkiss, A. et al: Making database systems usable. In: Proc. of the ACM SIGMOD Int. Conf. on Management of Data (SIGMOD 2007), pp. 13-24, Beijing, China, 2007.
[7] Agrawal, R., Ailamaki, A. Bernstein, P. A., et al.: The Claremont Report on Database Research. In: Communications of the ACM (CACM), vol 52, no 6, pp. 56-65, June 2009.
[8] Chaudhuri, S., Ganti, V., Kaushik, R.: A Primitive Operator for Similarity Joins in Data Cleaning. In: Proc. of the 22nd Intl. Conf. on Data Engineering (ICDE 2006), p. 5, Atlanta, USA, 2006.
[9] Sarawagi, S., Kirpal, A.: Efficient Set Joins on Similarity Predicates. Proc. of the ACM SIGMOD International Conference on Management of Data (SIGMOD 2004), pp. 743-754 Paris, France, 2004.
[10] Augsten, N., Böhlen, M. H., Gamper, J.: Approximate Matching of Hierarchical Data Using pq-Grams. In: Proc. of the 31st Intl. Conf. on Very Large Data Bases, pp. 301-312, Trondheim, Norway, 2005.
[11] Amer-Yahia, S., Lalmas, M.: XML Search: Languages, INEX and Scoring. In:SIGMOD Record,vol. 35, no 4, pp. 16-23, Dec. 2006.